Базовые понятия бэкенд-разработки: протоколы, параллелизм и модели конкурентности
Введение. Начинающему бэкенд-разработчику важно понимать, как устройства и программы общаются по сети, а также как эффективно выполнять несколько задач одновременно на сервере. В этой статье мы последовательно разберём три ключевые темы: сетевые протоколы соединения (HTTP, TCP, UDP, FTP), параллелизм (и его отличие от многозадачности) и модели параллелизма (потоки, процессы, событийная модель, асинхронность). Теория будет подкреплена понятными метафорами, диаграммами, примерами кода, а также практическими советами по отладке, тестированию и проектированию concurrent-систем.
1. Протоколы соединения: HTTP, TCP, UDP, FTP
Что такое сетевой протокол? Это набор правил, определяющих формат и порядок обмена сообщениями между участниками сети. Разные протоколы предназначены для разных уровней взаимодействия. Например, TCP и UDP работают на транспортном уровне и определяют, как доставлять данные, а HTTP и FTP работают на прикладном уровне и определяют смысл передаваемых данных (веб-страницы, файлы и т.д.). Чтобы разобраться, чем отличаются эти протоколы, рассмотрим эталонную модель OSI – концепцию, разделяющую сетевое взаимодействие на семь условных уровней. Каждый уровень решает свою задачу и использует сервисы нижележащего уровня. Ниже приведены уровни OSI и примеры относящихся к ним протоколов:
- Уровень 1: Физический. Передача битов по среде (физические сигналы по кабелю, радио-волны и т.д.). Например: Ethernet (физические аспекты), Wi-Fi-радио.
- Уровень 2: Канальный. Передача кадров (frame) внутри одной локальной сети, обеспечение обнаружения ошибок. Протоколы: Ethernet (канальный аспект), Wi-Fi MAC, PPP.
- Уровень 3: Сетевой. Маршрутизация пакетов между узлами в разных сетях. Протоколы: IP (Internet Protocol), ICMP (ping), маршрутизационные протоколы.
- Уровень 4: Транспортный. Надёжная или ненадёжная доставка данных между приложениями. TCP (надёжный, с установлением соединения) и UDP (ненадёжный, без соединения) — классические транспортные протоколы
- Уровень 5: Сеансовый. Управление сеансом связи (установка, поддержание и завершение сеанса, синхронизация диалога). В веб-разработке явных сеансовых протоколов обычно нет, эту роль берёт на себя прикладной уровень (например, сессии в HTTP реализуются приложением).
- Уровень 6: Представления. Преобразование данных для совместимости (форматы, шифрование, сжатие). Например: SSL/TLS шифрование (его можно отнести к этому уровню), сериализация JSON/XML.
- Уровень 7: Прикладной. Непосредственно приложения и высокоуровневые протоколы обмена данными. HTTP (веб-страницы, API), FTP (передача файлов), SMTP (электронная почта), DNS (преобразование имен) и др. работают на прикладном уровне
Примечание: На практике часто используется упрощённая модель TCP/IP из 4-х уровней (соединяя некоторые уровни OSI), но для понимания концепций подойдёт и OSI. Главное — разные протоколы “живут” на разных уровнях. Например, когда браузер запрашивает страницу по HTTP, запрос проходит вниз через уровни: приложение (HTTP) → транспорт (TCP) → сеть (IP) → канальный (Ethernet) → физический (сигналы). На сервере пакет поднимается вверх по уровням до HTTP. Такая многоуровневая инкапсуляция данных позволяет разделить ответственность: каждый протокол отвечает за свою часть задачи.
TCP vs UDP: надёжность и скорость передачи
Для транспортного уровня ключевой выбор – использовать TCP или UDP. Оба протокола доставляют данные от одного приложения к другому, но делают это по-разному:
- TCP (Transmission Control Protocol) – обеспечивает надёжную, порядковую и проверенную доставку потоков байт. Перед отправкой данных устанавливается соединение (трёхэтапное рукопожатие). TCP контролирует доставку: если пакет потерялся, он будет отправлен заново; данные приходят получателю строго в том порядке, в котором отправлены. Благодаря этому HTTP и многие приложения используют TCP – для них важно получить все данные целиком и в нужной последовательности (никто не хочет открыть веб-страницу и недосчитаться половины HTML-кода!). Минус TCP – более высокая задержка и накладные расходы на служебные данные, так как требуется подтверждать получение и управлять потоком данных.
- UDP (User Datagram Protocol) – обеспечивает ненадёжную, безустановочную передачу датаграмм (отдельных пакетов). Здесь нет предварительного установления соединения и нет гарантии доставки: отправитель просто “бросает” пакеты в сеть, как получится. Если какие-то потеряются – протокол этого не отслеживает. Зато UDP быстрее и проще: нет лишних подтверждений, меньше задержек. UDP подходит для приложений, где важнее скорость, чем абсолютная точность доставки. Пример: онлайн-игры, стриминг аудио/видео, звонки VoIP – лучше получить некоторые пакеты с небольшим опозданием, чем ждать повторной доставки потерянных и тормозить воспроизведение. Потеря пары кадров видео или миллисекунд звука не критична, их можно проигнорировать или заменить, зато связь будет более实时овой. VPN-протоколы также часто работают поверх UDP ради минимальной задержки. Недостаток UDP – приложению самому приходится заботиться о надёжности, если это нужно (например, реализовывать свои квиты или просто мириться с потерями).
Чтобы интуитивно понять разницу между TCP и UDP, представьте, что коллега попросил вас поделиться документом. TCP-подход: вы аккуратно несёте бумажный документ через весь офис и лично в руки передаёте коллеге – надёжно, хоть и медленно. UDP-подход: вы, не вставая со своего места, кидаете папку через всю комнату в сторону стола коллеги – может, долетит быстрее, но есть риск, что листы разлетятся или папка упадёт не туда. Первый способ гарантирует целостность доставки, второй – экономит время, но качество доставки не гарантировано.
Важно отметить, что HTTP почти всегда работает поверх TCP, потому что веб-страницы, файлы и данные API должны доставляться без искажений и потерь. Если какой-то фрагмент страницы потеряется по дороге, HTTP-протокол сам по себе не умеет запросить его повторно – эту задачу решает TCP. (В новейшей версии HTTP/3 используется протокол QUIC поверх UDP, который сам обеспечивает надёжность, но это особый случай.) UDP же применяется для протоколов, где заложена толерантность к потерям – напр. DNS может использовать UDP: если ответ не пришёл, просто повторит запрос или попробует другой сервер, и это быстрее, чем устанавливать TCP-соединение ради короткого сообщения.
Пример использования TCP и UDP. В веб-разработке вы встретитесь с TCP каждый раз, когда делаете запрос к API или открываете сайт – установится TCP-соединение на порт (80 для HTTP или 443 для HTTPS), далее пойдёт HTTP-трафик. С UDP вы можете столкнуться при работе, например, с службами стриминга или при взаимодействии с внешними сервисами через протоколы типа DNS. Если вы пишете свой игровой сервер, то ради скорости можете обмениваться пакетами по UDP, но тогда придётся самому думать о проверках (например, добавлять номера последовательности, чтобы отсеивать устаревшие или дубликаты). В большинстве же случаев в бэкенде достаточно понимать, что TCP = надёжно и упорядоченно, UDP = быстро, но ненадёжно.
HTTP vs FTP: прикладные протоколы для веб-страниц и файлов
Перейдём к прикладному уровню. HTTP (HyperText Transfer Protocol) и FTP (File Transfer Protocol) – оба протокола предназначены для передачи файлов и данных между клиентом и сервером, но у них разный контекст применения и поведение.
HTTP – это основа Всемирной паутины. Браузеры и веб-клиенты используют HTTP для запроса страниц, изображений, JSON-данных от серверов и т.д. Отличительные черты HTTP: он без сохранения состояния (stateless) и запрос-ответный. Это значит, что каждый HTTP-запрос (например GET /index.html) выполняется отдельно: клиент открывает соединение (обычно TCP), отправляет запрос и получает ответ, после чего соединение может быть закрыто. Сервер не сохраняет никакого контекста между отдельными запросами (если нужна “память” о клиенте, она достигается другими средствами – сессиями, куки, токенами и т.п.). Такая архитектура упрощает масштабирование – любой запрос можно обработать независимо на любом сервере. HTTP по умолчанию не требует аутентификации на уровне протокола: любой может послать запрос на публичный URL. При необходимости проверки прав доступа это реализуется либо на уровне приложения (напр. токены в заголовках), либо средствами расширения протокола (HTTP-авторизация, cookies). HTTP достаточно простой и гибкий: передаёт не только гипертекст, но и любые данные (JSON, XML, файлы) – поэтому на нём строят REST API, GraphQL и другие веб-сервисы. Один недостаток – сам по себе HTTP не шифрует данные и не проверяет целостность, всё передаётся открытым текстом. Поэтому для безопасности всегда используйте HTTPS – HTTP поверх TLS-шифрования.
FTP – один из старейших интернет-протоколов, специально разработанный для передачи файлов. Он более “состояниевый”: клиент устанавливает FTP-сеанс с сервером и поддерживает управление сессией. Обычно при подключении нужен логин и пароль (или анонимный вход). Главное отличие FTP – он использует две отдельные TCP-связи: командный канал (порт 21 по умолчанию) для отправки команд (типа LIST, GET filename и т.п.) и канал данных (порт 20 или динамический) для непосредственной передачи файлов. Такая архитектура сложнее для настройки (особенно с брандмауэрами/NAT), но исторически позволяла, например, передавать несколько файлов подряд, не устанавливая новое соединение на каждый, и эффективно возобновлять прерванные передачи. FTP хорош для обмена большими файлами и пакетной передачи (например, выгрузить сразу каталог файлов). Он был популярен когда-то для загрузки файлов на хостинги, в архивах ПО и т.д. Сейчас его используют гораздо реже, в основном внутри корпоративных сетей или если нужен публичный файловый сервер. Основные минусы FTP: отсутствие шифрования (вся аутентификация и данные — простым текстом, легко перехватить) и сложность прохождения через NAT/фаервол (из-за отдельного канала данных, который может открываться со стороны сервера). Существуют улучшения – FTPS (FTP over SSL) добавляет шифрование, SFTP (SSH File Transfer Protocol) работает поверх SSH и вообще по сути другой протокол, решающий проблему безопасности. Но если говорить про классический FTP, помните, что он не безопасен.
Сравнение HTTP и FTP: Оба протокола работают поверх TCP, обеспечивая надёжную передачу данных, но HTTP оптимизирован для клиент-серверных запросов небольших ресурсов, а FTP – для более длительных сеансов передачи больших объёмов данных. HTTP быстрее устанавливает соединение и обычно быстрее на мелких файлах (можно параллельно качать ресурсы с разных серверов, браузеры именно так делают). FTP же может быть эффективнее для передачи большого файла целиком или множества файлов, так как держит соединение открытым и может по команде переключаться между разными файлами, и у него есть возможность продолжить прерванную загрузку с места разрыва. Однако сегодня HTTP/2 и HTTP/3 научились мультиплексировать множество запросов в одном соединении, сжимать заголовки и т.д., поэтому HTTP вполне справляется и с передачей больших объёмов. Кроме того, современные загрузчики файлов поддерживают докачку по HTTP (через Range-заголовки). Поэтому сейчас почти всё передаётся по HTTP/HTTPS, а FTP стал нишевым. К тому же настройка FTP-сервера сложнее, чем просто выложить файлы по HTTPS. С другой стороны, FTP до сих пор может использоваться администраторами для загрузки файлов на сервер, резервного копирования, в случаях, когда нужен простой файловый доступ без веб-интерфейса.
Применение на практике: Вы, как бэкенд-разработчик, скорее всего будете ежедневно работать с HTTP – писать обработчики запросов, формировать ответы API, разбираться с кодами ответа (200 OK, 404 Not Found, 500 Internal Server Error и т.д.). Понимание, что HTTP работает поверх TCP, поможет вам, например, понимать влияние сетевых задержек (TCP требует установить соединение — “рукопожатие” — это ~1–2 дополнительного RTT). Вы также должны знать, что браузеры ограничивают количество одновременных TCP-соединений к одному домену, поэтому бэкенд может использовать разные субдомены для параллельной загрузки ресурсов (менее актуально с HTTP/2, где всё идёт по одному соединению). С FTP вы можете столкнуться, если, например, вам понадобилось интегрироваться с устаревшей системой, рассылающей данные по FTP, или выгружать отчёты для клиентов на FTP-сервер. Тогда пригодятся знания команд FTP-протокола (USER, PASS, STOR, RETR и т.д.) и особенности пассивного/активного режимов (два режима открытия data-канала). В современном вебе же для передачи файлов пользователям проще использовать HTTP(S) – например, выдавать временную ссылку на загрузку файла, вместо организации FTP-доступа.
Анализ сетевого трафика и отладка соединений
Разработчику полезно уметь “ заглядывать внутрь” сетевого обмена. Это помогает понять, всё ли корректно уходит и приходит, и где может быть проблема (настроек сервера, сети или приложения). Рассмотрим несколько инструментов и подходов:
- Wireshark. Мощный графический анализатор трафика. Позволяет в реальном времени захватывать пакеты, проходящие через сетевой интерфейс, и исследовать их побайтово. Wireshark раскладывает каждый пойманный пакет по уровням OSI. Например, вы отправили запрос на http://example.com – в захвате вы увидите Ethernet-фрейм (канальный уровень) с вложенным IP-пакетом (сетевой уровень) от вашего IP к IP сервера, внутри него – TCP-сегмент (транспортный) на порт 80, а уже внутри – данные HTTP-протокола (прикладной уровень) с строкой GET / HTTP/1.1 и заголовками. Wireshark подсветит разные уровни разными цветами, покажет, сколько байт на каждом уровне заголовков, и т.д. Это наглядно демонстрирует концепцию инкапсуляции данных. Вы сможете убедиться, что, скажем, при открытии HTTPS-сайта идёт TLS Handshake (протокол уровня представления) поверх TCP. Или, например, можете отфильтровать все пакеты UDP и увидеть, как проходит DNS-запрос (UDP пакет на порт 53). Пример трассировки: при заходе на google.com сначала пойдут несколько DNS-запросов, чтобы получить IP-адрес сайта (они будут видны как UDP-пакеты на порт 53 с содержимым “Standard query A google.com”). Затем установится TCP-соединение с полученным IP на порт 443, будет TLS-рукопожатие, и потом уже пойдут зашифрованные HTTP/HTTPS данные. Всё это можно проследить в Wireshark, что очень поучительно для понимания сетевых процессов.
- Traceroute. Утилита (traceroute в Linux, tracert в Windows) для трассировки маршрута до узла. Она показывает последовательность промежуточных маршрутизаторов (хопов), через которые проходят пакеты по пути к целевому серверу. Это достигается отправкой пакетов с постепенно увеличиваемым TTL (time-to-live) и получением ответов ICMP “Time Exceeded” от маршрутизаторов. Для бэкенд-разработчика traceroute полезен, когда нужно понять, где возникает задержка или потеря пакетов на пути к серверу (например, между какими сегментами сети). Traceroute работает на сетевом уровне (IP/ICMP/UDP) и не зависит от приложений – он показывает топологию маршрута. Если ваш сервер расположен далеко (например, на другом континенте), traceroute покажет, через сколько узлов и какие сети идут данные – отсюда можно примерно понять, какова задержка по физическому пути.
- Ping. Простая утилита для проверки доступности узла. Отправляет ICMP Echo Request (сетевой уровень) и ждет Echo Reply. Показывает время туда-обратно (RTT). Если пинги не проходят – значит, либо сеть недоступна, либо сервер отключён/не отвечает на ICMP (такое бывает из-за настроек брандмауэра). Ping не скажет, почему нет связи, но быстро даст понять сам факт проблемы с соединением.
- Просмотр сырого HTTP. Иногда полезно увидеть сырые HTTP-запросы и ответы. Для этого можно использовать командную строку: например, curl -v http://example.com покажет подробный обмен (что отправлено, что получено, со всеми заголовками). Или даже открыть сокет вручную: подключиться по TCP к серверу (например, telnet example.com 80 или nc example.com 80) и вручную ввести HTTP-команды (GET / HTTP/1.1 и т.д.) – сервер вернёт сырой HTML. Это помогает убедиться, что сервер вообще отвечает, и посмотреть, не искажаются ли данные по пути.
Итак, сетевые протоколы – это язык, на котором общаются компьютеры. HTTP – “язык веба”, FTP – “язык передачи файлов старой школы”, TCP – надёжный курьер, UDP – экспресс-доставка без гарантии. Понимая, на каком уровне что происходит, вы легче найдете причину проблем: будь то баг в коде обработки HTTP-запроса, сбой соединения TCP (например, Connection reset), или сетевые неполадки на уровне маршрутизации. В дальнейших разделах мы переключимся с уровня сети на уровень выполнения программ, и поговорим о том, как бэкенд может одновременно делать много дел.
2. Параллелизм: зачем он нужен и чем отличается от многозадачности
Когда вы запускаете программу, она обычно выполняется последовательно, шаг за шагом. Многозадачность (конкурентность) означает, что несколько задач могут выполняться в одном периоде времени, чередуясь или параллельно. Параллелизм же – это когда задачи действительно исполняются одновременно в один момент (требуются несколько ядер процессора или несколько машин). Грубо говоря, многозадачность — это умение делать много дел, переключаясь между ними, а параллелизм — выполнение нескольких дел одновременно. Зачем это нужно на бэкенде? Представьте сервер, к которому одновременно обращаются десятки пользователей. Если обрабатывать их запросы строго по очереди, то каждый следующий будет ждать, пока закончатся все предыдущие – производительность и скорость отклика резко падают. Параллелизм решает эту проблему: сервер может обслуживать множество запросов одновременно, эффективно используя ресурсы.
Вот простая метафора: у вас есть кухня и заказы на 10 разных блюд. Синхронный однозадачный подход – один повар готовит все блюда по очереди: сначала первое блюдо целиком, потом второе и т.д. Клиенты, сделавшие 10-й заказ, будут ждать очень долго! Конкурентный подход – один повар жонглирует задачами: например, поставил суп вариться (ждёт, пока сварится), в это время нарезает салат, потом возвращается к супу и т.д. Он не делает строго одно блюдо за раз, а чередует работы, не сидит без дела во время ожидания. Параллельный подход – нанять нескольких поваров, которые будут готовить разные блюда одновременно: пока первый варит суп, второй жарит стейк, третий режет салаты и так далее. В идеале 10 поваров справятся с 10 заказами примерно за то же время, что один повар делал бы 1 заказ. Многозадачность – это как раз первый случай (один повар переключается между задачами), параллелизм – второй (несколько поваров трудятся параллельно). Конечно, в реальности есть накладные расходы (посуды на всех может не хватать – аналог разделяемых ресурсов, повара могут мешать друг другу – аналог синхронизации), но модель понятна.
Теперь перенесём это на бэкенд-системы. Допустим, наш сервер должен одновременно обработать запросы от множества клиентов, сходить за данными в базу, выполнить вычисления и вернуть ответы. Если делать это строго последовательно (без параллелизма) – один запрос выполняется, все остальные ждут. Производительность системы ограничена скоростью обработки одного запроса. Если же использовать параллелизм, сервер может отправить несколько запросов в базу одновременно, заниматься обработкой нового запроса, пока предыдущий ждёт ответ от внешнего сервиса, и т.д. Это резко повышает пропускную способность (throughput). Например, при доступе к базе данных основное время запрос ждёт I/O – в этот момент CPU простаивает. Конкурентная (асинхронная) модель исполнения позволит использовать это время ожидания с пользой – заняться другим запросом. Практика показывает, что без параллелизма современный бэкенд просто не справится с нагрузкой.
Еще один аспект – многопоточность vs многопроцессность vs асинхронность (о них подробнее в следующем разделе). Исторически первым решением для параллелизма были процессы (сам операционная система может запускать несколько процессов “параллельно” – на самом деле быстро переключая одно ядро между ними, или на разных ядрах действительно одновременно). Потом появились потоки внутри процесса – более лёгкие “подзадачи”, разделяющие память одного приложения. А асинхронность и событийный цикл – это вообще иной подход: когда по сути один поток, но он сам знает, когда ему можно “приостановиться” и переключиться на другую задачу, чтобы не сидеть без дела. У каждого подхода есть плюсы и минусы, поэтому и важно понимать разницу.
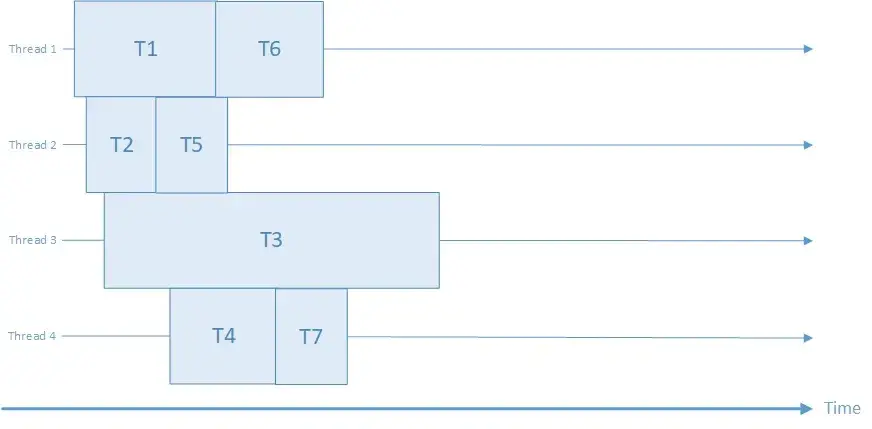
Посмотрим, как выглядит выполнение задач в однопоточном и многопоточном режиме:
На диаграмме показана однопоточная последовательная обработка четырёх задач (T1…T4) одним потоком. Поток (Thread 1) выполняет задачу T1, затем T2, потом T3 и T4 последовательно во времени. Пока одна задача не завершится, следующая не начнётся. Например, если T2 вынуждена ждать ввод-вывод (пустой промежуток), процессор простаивает до окончания T2. Такой подход прост, но неэффективен при ожиданиях – остальные задачи вынуждены ждать своей очереди.

На этой диаграмме многопоточная параллельная обработка: несколько потоков (Thread 1…Thread 4) выполняют задачи одновременно. Задачи T1…T7 распределены между потоками и перекрываются по времени. Например, пока Thread 1 занят задачей T1, параллельно Thread 2 выполняет T2, Thread 3 – T3 и Thread 4 – T4; затем потоки берут следующие задачи. В идеале (при наличии достаточного числа ядер CPU) задачи выполняются действительно одновременно, ускоряя общую работу. Даже на одном ядре система может чередовать потоки, создавая иллюзию параллельности (конкурентность).
Для сервера параллелизм означает, что он может одновременно обрабатывать несколько запросов. Если в однопоточном варианте один медленный запрос (например, читающий большой файл) задерживает все остальные, то при параллелизме другие запросы продолжат выполняться на других потоках или во время ожидания диска. Это критически важно для масштабируемости и отзывчивости бэкенда. Например, веб-сервер без параллелизма смог бы обслуживать только одного клиента за раз – очевидно, этого недостаточно. С параллелизмом тысячи клиентов могут получать ответы почти одновременно.
Разберём, как параллелизм применяется в разных технологиях бэкенда – Python, Node.js и Java – и приведём небольшие примеры кода.
Пример: параллелизм в Python (потоки и async/await)
В Python есть два основных подхода к выполнению нескольких задач сразу: многопоточность (используя threading или multiprocessing) и асинхронность (используя asyncio с ключевыми словами async/await). В традиционной многопоточности создаются несколько потоков выполнения, которые планируются операционной системой. В асинхронном подходе код сам кооперативно чередует задачи, используя цикл событий (event loop) – по сути, один поток, который переключается между задачами во время ожидания операций ввода-вывода.
Начнём с многопоточности. Допустим, мы хотим вычислить или вывести что-то в нескольких потоках параллельно:
import threading, time
def worker(name):
print(f"Старт потока {name}")
time.sleep(1) # имитация долговременной задачи (1 секунда)
print(f"Завершение {name}")
# Создаём два потока
t1 = threading.Thread(target=worker, args=("A",))
t2 = threading.Thread(target=worker, args=("B",))
t1.start()
t2.start()
# Ждём завершения обоих потоков
t1.join()
t2.join()
print("Оба потока завершены")
Вывод этой программы будет недетерминированным по порядку, но, например:
Старт потока A
Старт потока B
Завершение A
Завершение B
Оба потока завершены
Важно, что поток B начал выполняться, не дожидаясь завершения A – сообщения “Старт B” и “Завершение B” могут появиться, пока A ещё спит. Оба потока заснули на time.sleep(1) одновременно и проснулись примерно одновременно через секунду. Если бы мы выполняли эти задачи последовательно (без потоков), общее время было бы ~2 секунды, а с двумя потоками – ~1 секунда (оба спали параллельно). Таким образом, многопоточность в Python позволяет конкурентно выполнять задачи, особенно когда они чем-то блокируются (ожидают).
Однако у Python (в реализации CPython) есть особенность: Глобальная блокировка интерпретатора (GIL). GIL не позволяет одновременно выполнять байт-код Python более чем одному потоку внутри одного процесса. Это означает, что при чисто CPU-нагруженных задачах потоки не дадут прироста на нескольких ядрах – они всё равно выполняются по одному за раз. Но при наличии операций ввода-вывода (файлы, сеть, задержки) потоки отлично помогают: один поток ждёт файл, в это время другой вычисляет или тоже ждёт что-то своё – GIL быстренько переключается между ними. Если же вам нужен настоящий параллелизм на все ядра для тяжёлых вычислений, Python предлагает многопроцессность – модуль multiprocessing позволяет запустить несколько процессов Python, каждый со своим GIL, и загрузить несколько CPU на 100%. Но обмен данными между процессами сложнее (через очереди, пайпы), поэтому в рамках одного процесса часто используют альтернативу – асинхронность.
Асинхронное программирование в Python (модуль asyncio) позволяет писать код, который не блокирует поток во время ожидания. По сути, работает цикл событий, который управляет множеством сопрограмм (coroutines). Когда сопрограмма должна ждать (например, ответ от сервера или таймер), она добровольно отдаёт управление циклу, и тот может запустить другую сопрограмму в это время. Всё это происходит в одном (главном) потоке, без создания новых системных потоков.
Пример эквивалентной задачи на asyncio:
import asyncio
async def worker(name):
print(f"Начало задачи {name}")
# имитируем асинхронную задержку 1 секунду (не блокирует поток)
await asyncio.sleep(1)
print(f"Конец задачи {name}")
async def main():
# запускаем две задачи конкурентно
await asyncio.gather(worker("A"), worker("B"))
print("Обе задачи завершены")
asyncio.run(main())
Вывод будет похож на многопоточный пример:
Начало задачи A
Начало задачи B
Конец задачи A
Конец задачи B
Обе задачи завершены
Обратите внимание: выполнение обеих задач переплетается, хотя у нас нет двух потоков (всё выполняется в одном потоке event loop). Когда worker("A") достигает await asyncio.sleep(1), управление возвращается циклу событий, и тот сразу же запускает worker("B") до её паузы, после чего цикл ждёт, когда истечёт таймер sleep у обоих задач, и затем продолжает их. В итоге обе задачи заняли в сумме ~1 секунду, а не 2, то есть мы достигли конкурентности без потоков. В Python async/await очень удобен для сетевого ввода-вывода: например, можно одновременно сделать десятки запросов к разным URL и ждать их ответов, не блокируя поток, а когда любой из них ответит – обработать и продолжить другие.
Когда использовать потоки, а когда async? Правило: если у вас много внешних ожиданий (IO-bound: запросы к БД, HTTP-запросы к внешним сервисам, ожидание пользователей), то async/await позволит написать очень эффективный код, который не простаивает впустую. Асинхронность избегает расходов на создание потоков и переключение контекста ОС, позволяя одной ОС-потоке обслуживать тысячи соединений (пример – асинхронные фреймворки типа FastAPI/uvicorn, Tornado, aiohttp в Python). Если же у вас тяжёлая CPU-нагрузка (CPU-bound, например, обработка изображений, сложные вычисления), async не поможет – вам придётся либо вынести задачу в отдельный процесс (пул процессов), либо использовать потоки, но с учётом GIL лучше процессы для параллелизма на нескольких ядрах. В Python зачастую комбинируют подходы: основной сервер на asyncio обслуживает запросы, а для тяжёлой задачи может из пула запустить внешние процессы/трейды (например, через concurrent.futures.ThreadPoolExecutor или ProcessPoolExecutor). Таким образом достигается и высокая отзывчивость, и использование всех ресурсов процессора.
Пример: параллелизм в Node.js (событийный цикл, неблокирующий I/O)
Node.js изначально построен на событийной модели. В Node ваш код JavaScript выполняется в одном основном потоке, а параллелизм достигается за счёт неблокирующего ввода-вывода и асинхронных колбэков/обещаний (promises). Node.js запущен под капотом на движке V8 и библиотеке libuv, которая реализует цикл событий и пул потоков для некоторых операций. Но принципиально, когда вы пишете на Node, вы предполагаете, что весь ваш код выполняется однопоточно, поэтому нет гонок данных в самом JS-коде – это упрощает жизнь. При этом Node способен обслуживать огромное число соединений, потому что когда одно из них ждёт результат I/O, ваш JS-код просто ничего не делает, а Node “под капотом” обрабатывает события от сетевых сокетов и по готовности вызывает ваш колбэк.
Простой пример демонстрации цикла событий:
console.log("Начало");
// Запланировать асинхронную функцию через 1 секунду
setTimeout(() => {
console.log("Таймер сработал");
}, 1000);
console.log("Конец");
Вывод в Node.js будет:
Начало
Конец
Таймер сработал
Как видите, строка "Конец" выводится до того, как выполнился колбэк таймера, хотя задержка таймера всего 1 секунда. Это потому, что вызов setTimeout не блокирует поток: Node зарегистрировал таймер и сразу продолжил выполнение дальнейшего кода. Основной поток дошёл до конца программы, а спустя 1 сек через цикл событий выполнилась отложенная функция. Если бы вместо setTimeout мы сделали синхронную задержку (например, в JS можно искусственно создать блокирующий цикл на 1 сек), то "Конец" вывелся бы только через секунду. В этом и суть: неблокирующие операции позволяют Node.js быть высокопроизводительным. Функции ввода-вывода (работа с файлами, сетевые запросы, обращения к базе) в Node обычно имеют асинхронный вариант, который принимает колбэк или возвращает промис. Когда вы вызываете, например, fs.readFile("file.txt", callback), Node отправляет запрос к операционной системе прочитать файл, и ваш JS-код тут же продолжает работу; как только файл будет прочитан (через системный поток ввода-вывода), Node.js получит сигнал и вызовет ваш callback с результатом. Всё это время основной поток не простаивал – он мог обслуживать другие события (другие запросы).
Таким образом, Node.js применяет параллелизм “под капотом”, но предоставляет программисту удобную однопоточную среду. Вы не мучаетесь с mutex’ами – у вас просто нет конкурентных потоков в JS (если специально не использовать Worker Threads, которые появились для специфических случаев). Конкурентность достигается кооперативно: вы пишете код так, чтобы не делать долгих блокирующих вычислений; если задача тяжёлая, её нужно вынести в отдельный воркер или процесс. Зато обслуживание тысячи одновременных сетевых соединений – тривиальная вещь для Node, потому что пока 999 соединений ждут данных, 1 активно обрабатывается, потом переключаемся и т.д. Например, популярный веб-сервер NGINX работает по схожему принципу (событийный цикл на C), благодаря чему славится способностью держать огромное количество одновременных подключений.
В Node.js мы тоже можем использовать пул процессов (модуль cluster) или Worker Threads для CPU-bound задач, но для большинства задач бэкенда (обработка HTTP-запросов, взаимодействие с БД) хватает асинхронной модели. Код выглядит последовательным (особенно с появлением async/await в JS), а работает эффективно. Ниже небольшой пример асинхронного HTTP-сервера в Node (для понимания):
const http = require('http');
http.createServer((req, res) => {
// Каждое входящее req событие обрабатывается в колбэке (один поток на все)
if (req.url === '/data') {
// имитация асинхронной операции, например чтение из базы
setTimeout(() => {
res.end("Вот ваши данные");
}, 100);
} else {
res.end("OK");
}
}).listen(3000);
console.log("Сервер запущен на порту 3000");
Этот сервер, запущенный в одном процессе, способен параллельно отвечать на множество запросов. Если поступит запрос на /data, сервер инициирует асинхронный таймер на 100мс и тем временем может заняться другими запросами. Как только таймер сработает, ответ будет отправлен. Если в то же время пришёл ещё десяток запросов на /, они сразу получат ответ "OK", не дожидаясь завершения того таймера. В традиционном же многопоточном сервере (как в Java) каждое соединение держало бы поток, который либо работает, либо простаивает в ожидании. Node избегает простаивающих потоков – у него всего один основной поток, который всегда чем-то занят.
Итого, параллелизм в Node.js достигается через асинхронность и событийный цикл. Это требует от разработчика осторожности: нельзя выполнять долгие синхронные операции (они “заморозят” весь сервер). Но с этим ограничением Node прекрасно масштабируется по числу I/O-операций. Например, для чата или real-time приложения Node – отличный выбор: пока один клиент шлёт сообщение, Node может рассылать уведомления другим, не заводя сотни потоков.
Пример: параллелизм в Java (многопоточное программирование)
Java изначально разрабатывалась с поддержкой многопоточности как одного из ключевых возможностей. В отличие от Python, здесь нет GIL, и вы можете полноценно запускать потоки на всех ядрах. Типичный Java-бэкенд (например, на сервлете или Spring) использует пул потоков: для каждого входящего запроса из пула берётся поток и выполняет запрос. Поэтому если одновременно приходят 100 запросов, они распределяются, скажем, на 20 потоков пула и выполняются параллельно (пул берёт по мере освобождения). Кроме того, Java предлагает богатый набор утилит для синхронизации (synchronized, классы из java.util.concurrent), коллекции, безопасные в многопоточной среде (ConcurrentHashMap, BlockingQueue), высокоуровневые конструкции (Executors, Future/CompletableFuture для асинхронности). Поэтому в Java можно сочетать традиционную многопоточность с асинхронным стилем (например, CompletableFuture позволяет писать неблокирующий код, который под капотом может использовать потоки пула).
Рассмотрим простой пример создания потоков в Java:
public class ThreadDemo {
public static void main(String[] args) {
// Создаем задачу Runnable через лямбда-выражение
Runnable task = () -> {
String threadName = Thread.currentThread().getName();
System.out.println("Hello from " + threadName);
try {
Thread.sleep(1000); // имитируем работу 1 секунду
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Goodbye from " + threadName);
};
// Запускаем два потока с этой задачей
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
t1.start();
t2.start();
System.out.println("Threads started");
}
}
В этом коде мы определили задачу task, которая печатает приветствие, спит секунду и печатает прощание, сообщая имя потока. Затем создаём два потока t1 и t2 с одной и той же задачей и запускаем их. Примерный вывод может быть таким (порядок строк может меняться):
Threads started
Hello from Thread-0
Hello from Thread-1
Goodbye from Thread-0
Goodbye from Thread-1